1. 简介
Zookeeper缘起于非开源的Google的Chubby,雅虎模仿Chubby开发了ZooKeeper,实现了类似的分布式锁管理,并捐给了Apache,作为是Hadoop和Hbase的重要组件。
ZooKeeper是一种用于分布式应用程序的分布式开源协调服务,它主要是用来解决分布式应用中经常遇到的一些数据一致性问题。它的一致性、可靠性和容错性保证了其能够在大型分布式系统中稳定的表现,并不会因为某一个节点服务宕机而导致整个集群崩溃。它可提供的功能包括:配置维护、域名服务、分布式同步、组服务等。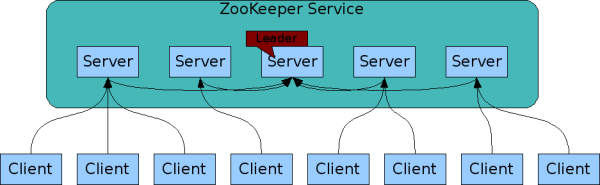
Zookeeper集群中的角色主要有:
- Leader:为zk集群的核心,负责集群内部的调度、投票的发起和决策和系统状态更新登。
- Follower:接收Client请求、转发请求给Leader和参与投票等。
- Observer:充当观察者角色,功能与Follower基本一致,不同点在于它不参与任何形式的投票,它只提供非事务请求服务。
Zookeeper维护一个具有层次关系的数据结构,类似于文件系统,名称是由斜杠(/)分隔的路径元素序列,ZooKeeper名称空间中的每个节点都由路径标识。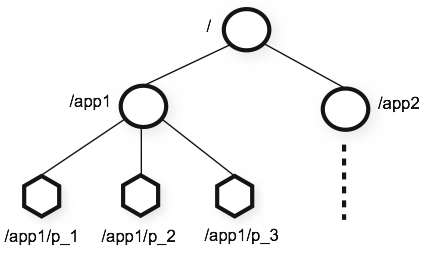
2. 安装配置
zookeeper的相关资源如下:
zookeeper的安装之前,需确保java环境运行正常。
zookeeper有三种搭建方式:单机模式、伪集群模式和集群模式。
2.1. 单机模式
解压:将下载好的zookeeper-*.tar.gz解压到指定安装目录下:1
2tar -zxvf zookeeper-3.4.10.tar.gz #解压zookeeper压缩包
cd zookeeper-3.4.10 #进入zookeeper根目录
主要目录结构:
- bin:一些执行脚本命令,其中,.sh为linux环境下脚本,.cmd为windows下脚本。
- conf:存放配置文件和日志配置文件。
- contrib:一些附加功能,用于操作zk的工具包。
- dist-maven:mvn编译后目录。
- docs:相关操作文档。
- lib:zk依赖的jar包。
- recipes:一些代码示例demo。
- src:源文件。
配置文件:
将conf目录下zoo_sample.cfg复制一份并重命名为zoo.cfg:1
cp conf/zoo_sample.cfg conf/zoo.cfg
修改配置文件zoo.cfg:1
2
3
4
5
6tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zookeeper-3.4.10/dataDir #zk数据保存目录
dataLogDir=/usr/local/zookeeper/zookeeper-3.4.10/dataLogDir #zk日志保存目录,当不配置时与dataDir一致
clientPort=2181 #客户端访问zk的端口
配置文件中参数详解见“3.配置文件详解”。
配置环境变量:
为方便操作,可对zk配置环境变量,linux环境下在/etc/profile文件最后追加:1
2
3ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/bin
export ZOOKEEPER_HOME PATH
为立即生效配置,通过执行如下命令:1
source /etc/profile
启动zk服务:1
zkServer.sh start
启动信息:1
2
3ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看zk状态:1
zkServer.sh status
输出状态信息:1
2
3ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: standalone #说明当前为单机模式
关闭zk服务:1
zkServer.sh stop
关闭信息:1
2
3ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
2.2. 伪集群模式
zookeeper还可以在单机上运行多个zk实例,实现单机伪集群的搭建,即单机环境下模拟zk集群的运行。
现在在单机上搭建一个3个节点的伪分布式环境,需要配置3个配置文件(zoo1.cfg、zoo2.cfg、zoo3.cfg,分别代表3个节点的配置信息)。在配置过程中,必须保证各个配置文件中的端口号(clientPort)不能冲突,zk数据及日志保存目录(dataDir、dataLogDir)也不能一样。除此之外,还需要在每个节点对应的dataDir中创建一个名为myid的文件,并写入一个数字以标识当前的zk实例。
在一台单机上部署3个节点的伪集群模式的zookeeper环境,假设3台zk服务分别为server1、server2和server3,对应3个配置文件分别为zoo1.cfg、zoo2.cfg和zoo3.cfg,这些重点的配置文件信息描述如下:
conf/zoo1.cfg:1
2
3
4
5
6
7
8
9
10
11tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zookeeper-3.4.10/cluster-data/dataDir1
dataLogDir=/usr/local/zookeeper/zookeeper-3.4.10/cluster-data/dataLogDir1
clientPort=2181
server.id=host:port1:port2,其中id为server id,对应myid;host为ip或主机名称;port1为用于followers连接到leader的端口; port2为leader选举时使用的端口.
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
创建myid文件,并写入server id:1
echo "1" > cluster-data/dataDir1/myid
conf/zoo2.cfg:1
2
3
4
5
6
7
8
9
10
11tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zookeeper-3.4.10/cluster-data/dataDir2
dataLogDir=/usr/local/zookeeper/zookeeper-3.4.10/cluster-data/dataLogDir2
clientPort=2182
server.id=host:port1:port2,其中id为server id,对应myid;host为ip或主机名称;port1为用于followers连接到leader的端口; port2为leader选举时使用的端口.
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
创建myid文件,并写入server id:1
echo "2" > cluster-data/dataDir2/myid
conf/zoo3.cfg:1
2
3
4
5
6
7
8
9
10
11tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zookeeper-3.4.10/cluster-data/dataDir3
dataLogDir=/usr/local/zookeeper/zookeeper-3.4.10/cluster-data/dataLogDir3
clientPort=2183
server.id=host:port1:port2,其中id为server id,对应myid;host为ip或主机名称;port1为用于followers连接到leader的端口; port2为leader选举时使用的端口.
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
创建myid文件,并写入server id:1
echo "3" > cluster-data/dataDir3/myid
启动zk服务:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17zkServer.sh start conf/zoo1.cfg
运行server1实例,输出信息如下:
ZooKeeper JMX enabled by default
Using config: conf/zoo1.cfg
Starting zookeeper ... STARTED
zkServer.sh start conf/zoo2.cfg
运行server2实例,输出信息如下:
ZooKeeper JMX enabled by default
Using config: conf/zoo2.cfg
Starting zookeeper ... STARTED
zkServer.sh start conf/zoo3.cfg
运行server3实例,输出信息如下:
ZooKeeper JMX enabled by default
Using config: conf/zoo3.cfg
Starting zookeeper ... STARTED
启动后,可通过jps命令,查看zk运行情况:1
2
3
418866 QuorumPeerMain
18967 Jps
18936 QuorumPeerMain
18894 QuorumPeerMain
其中,QuorumPeerMain为zk集群的启动入口类,用来加载配置启动QuorumPeer线程。
查看zk个节点状态:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17zkServer.sh status conf/zoo1.cfg
查看server1状态,输出信息如下:
ZooKeeper JMX enabled by default
Using config: conf/zoo1.cfg
Mode: follower
zkServer.sh status conf/zoo2.cfg
查看server2状态,输出信息如下:
ZooKeeper JMX enabled by default
Using config: conf/zoo2.cfg
Mode: leader
zkServer.sh status conf/zoo3.cfg
查看server3状态,输出信息如下:
ZooKeeper JMX enabled by default
Using config: conf/zoo3.cfg
Mode: follower
从返回的状态信息可知,server2为leader、server1和server3为follower。
2.3. 集群模式
在真实环境中,为提供可靠的zookeeper分布式环境,通常一台机器上只部署一个zk服务。在zk集群中,若超过半数以上的服务节点可用,则整个zk集群服务是可用的,故而其节点数通常为大于等于3的奇数(2n+1)。
现在分别在3台机器上搭建zk分部署环境,3台机器情况如下:
| zk服务标识 | ip | myid |
|---|---|---|
| server1 | 192.168.56.100 | 1 |
| server2 | 192.168.56.101 | 2 |
| server3 | 192.168.56.102 | 3 |
集群配置方式与上面两种方式类似,为方便操作可在每台机器上配置zookeeper的环境变量,每台机器上的配置文件也都相同。
conf/zoo.cfg:1
2
3
4
5
6
7
8
9
10
11tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zookeeper-3.4.10/dataDir
dataLogDir=/usr/local/zookeeper/zookeeper-3.4.10/dataLogDir
clientPort=2182
server.id=host:port1:port2,其中id为server id,对应myid;host为ip或主机名称;port1为用于followers连接到leader的端口; port2为leader选举时使用的端口.
server.1=192.168.56.100:2288:3388
server.2=192.168.56.101:2288:3388
server.3=192.168.56.102:2288:3388
在每台机器上的/usr/local/zookeeper/zookeeper-3.4.10/dataDir中创建myid文件,并写入server id:server1为1、server2为2、server3为3。
在每台机器上分别启动zk服务:1
zkServer.sh start
3. 配置文件详解
3.1. conf/zoo_sample.cfg:
zoo_sample.cfg为zookeeper的核心配置文件,需要将其修改为zoo.cfg。其中各个参数的解释如下:
3.1.1. Minimum Configuration(必要配置参数)
| 参数名 | 说明 |
|---|---|
| tickTime | 默认为2000。 zk中基本时间单位长度(ms),zk中的时间都以该时间为基础,是该时间的倍数,如最小的session过期时间就是tickTime的两倍。 服务器与服务器或客户端与服务器之间维持心跳的时间间隔,即每个tickTime会发送一个心跳,通过该心跳可以监视机器的工作状态、控制follower和leader的通信时间等。 |
| dataDir | 默认为/tmp/zookeeper。该默认目录仅为样例,不建议直接使用。 存储快照文件snapshot的目录,即保存数据的目录,默认情况下,zk会将写数据的日志文件也存储在该目录。 zk的数据在内存中以树形结构进行存储,而快照为每隔一段时间就会把整个DataTree的数据序列化后存储在磁盘中。 |
| clientPort | 默认为2181。 客户端连接zk服务器的端口,zk会监听这个端口,接受客户端的访问请求。 |
3.1.2. Advanced Configuration(可选的高级配置项,更细化的控制)
| 参数名 | 说明 |
|---|---|
| dataLogDir | (No Java system property) 存储事务日志文件的目录。默认情况下在没有配置该参数时,zk会将事务日志和快照数据都存储在dataDir中,但是实际中最好将这两者的分开存储。因为当zk进行频繁读写操作时,会产生大量事务日志信息,将这两者分开存储可以提高性能,当然分不同磁盘进行存储可以进一步提高整体性能。 在zk工作过程中,针对所有事务操作,在返回客户端“事务成功”的响应前,zk会保证已经将本次操作的事务日志写到磁盘上,只有这样,事务才会生效。 |
| globalOutstandingLimit | 默认为1000。(Java system property: zookeeper.globalOutstandingLimit) 最大请求堆积数,即等待处理的最大请求数量的限制。 当有很多客户端不断请求服务端时,可能导致请求堆积和内存耗尽,为避免这种情况,可通过设置该参数来限制同时处理的请求数。 |
| snapCount | 默认为100000。(Java system property: zookeeper.snapCount) 用于配置相邻两次数据快照之间的事务操作次数,即ZooKeeper会在snapCount次事务操作(事务日志输出)之后进行一次数据快照。当新增log条数(事务日志)达到 snapCount/2 + Random.nextInt(snapCount/2) 时(log条数在[snapCount/2+1, snapCount]区间),将触发一次快照,此时zk会生成一个snapshot.*文件,同时创建一个新的事务日志文件log.*,同时log计数重置为0,以此循环。 使用随机数的原因:让每个服务器生成快照的时间随机且可控,避免所有服务端同时生成快照(生成快照过程中将阻塞请求)。 |
| preAllocSize | 默认为64M,单位为KB。(Java system property: zookeeper.preAllocSize) 用于配置zk事务日志文件预分配的磁盘空间大小。每当剩余空间小于4K时,将会再次预分配,如此循环。如果生成快照比较频繁时,可适当减小snapCount大小。比如,100次事务会新产生一个快照,新产生快照后会用新的事务日志文件,假设每次事务操作的数据量最多1KB,那么preAllocSize设置为1000KB即可。故而preAllocSize常与snapCount相关协调配置。 |
| maxClientCnxns | 默认为60。3.4.0版本之前默认为10。(No Java system property) 限制单个客户端与单台服务器之间的并发连接数(在socket层级),根据IP区分不同的客户端。设置为0,可取消该限制。 配置该参数可用来阻止某种类型的DoS攻击,包括文件描述符资源耗尽。 |
| clientPortAddress | 无默认值。New in 3.3.0。 指定侦听clientPort的address(ipv4, ipv6 or hostname),默认情况下,clientPort会绑定到所有IP上。在物理server具有多个网络接口时,可以设置特定的IP。 |
| minSessionTimeout maxSessionTimeout | 默认为2*tickTime和20*tickTime。New in 3.3.0。(No Java system property) Session超时时间限制,如果客户端设置的超时时间不在这个范围(即2*tickTime~20*tickTime),那么会被强制设置为最大或最小时间。 |
| fsync.warningthresholdms | 默认为1000,单位为毫秒。New in 3.3.4。( Java system property: zookeeper.fsync.warningthresholdms) 当zk进行事务日志(WAL)fsync操作消耗的时间大于该参数,则在日志打印报警日志。 |
| autopurge.snapRetainCount | 默认为3。New in 3.4.0。(No Java system property) 配置清理文件时需要保留的文件数目,会分别清理dataDir和dataLogDir目录下的文件。因为client与zk交换时会产生大量日志,且zk也会将内存数据存储为快照文件,这些数据不会自动删除,通过autopurge.snapRetainCount和autopurge.purgeInterval这两个参数搭配使用可以自动清理日志。 |
| autopurge.purgeInterval | 默认为0,单位为小时。New in 3.4.0。(No Java system property) 清理频率,配置多少小时清理一次。需要填写一个大于等于1的整数,默认是0,表示不开启自动清理功能。 若在集群处于忙碌的工作状态时开始自动清理,可能会影响zk集群性能,由于zk暂时无法设置时间段(在集群不忙的时候)来开启清理,故而有时会直接禁用该功能,通过在服务器上配置cron来进行清理操作。 |
| syncEnabled | 默认为true。New in 3.4.6, 3.5.0。(Java system property: zookeeper.observer.syncEnabled) 观察者像参与者一样默认记录事务并将快照写入磁盘,这可以减少重新启动时观察者的恢复时间。可设置false来关闭该功能。 |
3.1.3. Cluster Options(集群控制参数)
| 参数名 | 说明 |
|---|---|
| electionAlg | 默认为3。(No Java system property) 配置zk的选举算法。“0”为基于原始的UDP的LeaderElection,“1”为基于UDP和无认证的的FastLeaderElection,“2”为基于UDP和认证的FastLeaderElection,“3”为基于TCP的FastLeaderElection。 目前,0、1和2的选举算法的实现已经弃用,并有意从下个版本中移除,故而该参数应该用处不大了。 |
| initLimit | 默认为10。(No Java system property) 集群中follower和leader之间初始连接时能容忍的最多心跳数(总时间长度即为10*2000=20000ms,即20s),当follower启动时会与leader建立连接并完成数据同步,leader允许follower在initLimit的心跳数内完成该工作。 通常使用默认值即可,但是随着集群数据量的增大,follower启动时与leader的同步时间也会随之增大,使之可能无法在规定时间内完成数据同步,故而此情况下需适当调大该参数。 |
| leaderServes | 默认为yes。(Java system property: zookeeper.leaderServes) 配置leader是否接受client连接请求。当zk集群超过3台机器,可以设置为“no”,让leader专注于协调集群中的机器,以提高集群性能。 |
| server.x=[hostname]:nnnnn[:nnnnn], etc | (No Java system property) “server.id=host:port1:port2” 表示不同ZK服务器的配置。这里的id为server id,对应myid;host为ip或主机名称;port1为用于followers连接到leader的端口;port2为leader选举时使用的端口(当electionAlg为0时,port2不再必要)。若要在单台机器上测试搭建集群服务,需要设置不同的端口,避免端口冲突。 |
| syncLimit | 默认为5。(No Java system property) 集群中follower和leader之间通信时能容忍的最多心跳数(总时间长度即为5*2000=10000ms,即10s),即follower和leader之间发送消息时请求和回应的最长时间不能超过syncLimit*tickTime毫秒。 在集群工作时,leader会与所有follower进行心跳检测来确认存活状态,若leader在syncLimit*tickTime时间范围内没有收到响应,则认为follower已经掉线,无法和自己进行同步。当集群网络质量较差(如延时问题和丢包问题等),可适当调大该参数。 |
| group.x=nnnnn[:nnnnn] | (No Java system property) 对整个大的zk集群进行分组,x为组id,nnnnn是zk集群中各个服务id。如果你给集群中的实例分组的话,各个组之间不能有交集,并且要保证所有组的并集就是整个zk集群。 若zk集群分为3组,只要其中两个是稳定的,整个集群状态即为稳定的(过半原则,有2n+1个组,只要有n+1个组是稳定状态,整个集群则为稳定状态);选举leader时,每组为一票,当组内大多数投票,则投票成功。 例子可见:http://zookeeper.apache.org/doc/current/zookeeperHierarchicalQuorums.html |
| weight.x=nnnnn | (No Java system property) 常与group搭配使用,用于调节组内单个节点的权重。默认每个节点的权重为1,若为0则不参与选举。 例子可见:https://www.jianshu.com/p/405f07b97550 |
| cnxTimeout | 默认为5,单位为秒。(Java system property: zookeeper.cnxTimeout) 用于为leader选举通知打开连接的超时时间。仅在electionAlg的值为3时有用。 |
| 4lw.commands.whitelist | 默认除了“wchp”和“wchc”之外的所有四字命令。New in 3.4.10。(Java system property: zookeeper.4lw.commands.whitelist) 配置四字命令白名单,zk不处理未出现在list上的四字命令。多个以逗号分隔,如:4lw.commands.whitelist=stat, ruok, conf, isro;若需开启所有命令,则为4lw.commands.whitelist=*。 |
| ipReachableTimeout | 时间值,单位为毫秒。New in 3.4.11。(Java system property: zookeeper.ipReachableTimeout) 配置当解析hostname时ip地址的可达超时时间。当解析hostname时,且hosts表和DNS服务中hostname对应着多个ip,则默认zk会使用第一个ip,且不会去检查可达性;而当该参数配置了一个大于0的值,zk则会依次判断hostname对应的所有ip是否可达(InetAddress.isReachable(long timeout)),若不可达,则判断下一个,若都不可达,则使用第一个ip。 |
| tcpKeepAlive | 默认为false。New in 3.4.11。(Java system property: zookeeper.tcpKeepAlive) 配置用来选举的TCP连接是否为长连接。true为开启长连接。 |
3.1.4. Authentication & Authorization Options(身份认证和相关授权的配置项)
| 参数名 | 说明 |
|---|---|
| zookeeper.DigestAuthenticationProvider.superDigest | 默认禁用。New in 3.2。(Java system property only: zookeeper.DigestAuthenticationProvider.superDigest) 允许zk集群管理员以“super”的身份来访问znode层级结构,且“super”用户没有ACL检查。“org.apache.zookeeper.server.auth.DigestAuthenticationProvider”可生成superDigest,其可通过调用参数“super:<password>”来实现。在启动集群中每台服务器时,可提供生成的“super:<data>”作为系统属性。zk客户端会传递一个“digest”和“super:<password>”认证数据进行身份认证。需要注意,认证数据会以普通文本(明文)的形式传递给服务器,建议仅在本地(非网络中)和加密连接中使用。 |
| isro | New in 3.4.0。 检查server是否处于只读状态。当回复“ro”时,代表在只读模式;当回复“rw”时,代表在非只读模式(可读可写)。 |
| gtmk | 获取当前10进制64位有符号数值形式的trace mask。 |
| stmk | 设置当前的trace mask。trace mask是为64位,每一位的标识表示开启或禁用server上特定类别的跟踪日志记录。Log4J必须设置为TRACE级别以看到trace日志信息。trace mask的每一位的含义如下: 0b0000000000:保留位,留以后用。 0b0000000010:记录client的请求, 不包括ping请求。 0b0000000100:保留位,留以后用。 0b0000001000:记录client的ping请求。 0b0000010000:记录当前leader的信息,不包括ping请求。 0b0000100000:记录client sessions的创建、移除和认证。 0b0001000000:记录向client sessions传递的监控事件。 0b0100000000: 保留位,留以后用。 0b1000000000: 保留位,留以后用。 默认的trace mask为0b0100110010。 调用stmk命令时, server会将设置后的trace mask以十进制数值的形式返回回来。一个使用perl调用stmk命令的例子: $ perl -e "print 'stmk', pack('q>', 0b0011111010)" | nc localhost 2181250 |
3.1.5. Experimental Options/Features(实验性配置项)
| 参数名 | 说明 |
|---|---|
| Read Only Mode Server | 默认为false。New in 3.4.0。(Java system property: readonlymode.enabled) 配置为true,zk启用只读模式服务支持。在这种模式下,ROM clients仍然可以从zk读取值,但是不能写入值并查看来自其他客户机的更改。更多细节参见ZOOKEEPER-784。 |
3.1.6. Unsafe Options(不安全配置项)
| 参数名 | 说明 |
|---|---|
| forceSync | (Java system property: zookeeper.forceSync) 默认情况下,zk要求先更新事务日志,再执行事务操作。若该参数设置为no,zk将不再需要等更新完事务日志后再执行事务操作。 |
| jute.maxbuffer | (Java system property: jute.maxbuffer) 配置可在一个znode中存储数据的最大容量。默认为0xfffff,或低于1M。注意若变更此值,所有server都要同步修改。 |
| skipACL | (Java system property: zookeeper.skipACL) 配置跳过ACL检查。这可以提高吞吐量,但会对所有人开放完全访问数据树,很不安全。 |
| quorumListenOnAllIPs | 若设置为true,zk服务将监听所有本地可用的ip地址,不仅仅是配置文件中server list。它会影响处理ZAB协议和 Fast Leader Election协议的连接。默认为false。 |
3.1.7. Communication using the Netty framework(使用Netty框架进行通信)
Netty是一个基于NIO的客户机/服务器通信框架,它简化了(通过直接使用NIO) java应用程序网络级通信的许多复杂性。此外,Netty框架内置了对加密(SSL)和身份验证(证书)的支持。这些都是可选的功能,可以单独打开或关闭。
在版本3.4之前,ZooKeeper一直都是直接使用NIO,但是在版本3.4及以后的版本中,Netty作为NIO(替换)的选项得到了支持。NIO仍然是默认值,但是基于Netty的通信可以通过将环境变量“zookeeper.serverCnxnFactory”设置为“org.apache.zookeeper.server.NettyServerCnxnFactory”来代替NIO。您可以在客户端或服务器上设置此项,或者两者都设置。
参考资料
[1] Zookeeper Overview. http://zookeeper.apache.org/doc/r3.4.10/zookeeperOver.html.
[2] ZooKeeper Administrator’s Guide. http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_configuration.
[3] zookeeper调优(遇到就添加). https://my.oschina.net/u/3049601/blog/1809785.
[4] zookeeper日志各类日志简介. https://www.cnblogs.com/jxwch/p/6526271.html.
[5] ZooKeeper: 简介, 配置及运维指南. https://www.cnblogs.com/neooelric/p/9230967.html.
[6] ZooKeeper学习第二期–ZooKeeper安装配置. https://www.cnblogs.com/sunddenly/p/4018459.html.